- Tue 10 December 2019
- Publication
- Link
- International Conference on Learning Representations 2021 (Oral, top 1.8% of submissions)
SMiRL: Surprise Minimizing RL in Unstable Environments
Glen Berseth, Daniel Geng, Coline Devin, Nicholas Rhinehart, Chelsea Finn, Dinesh Jayaraman, Sergey Levine  | 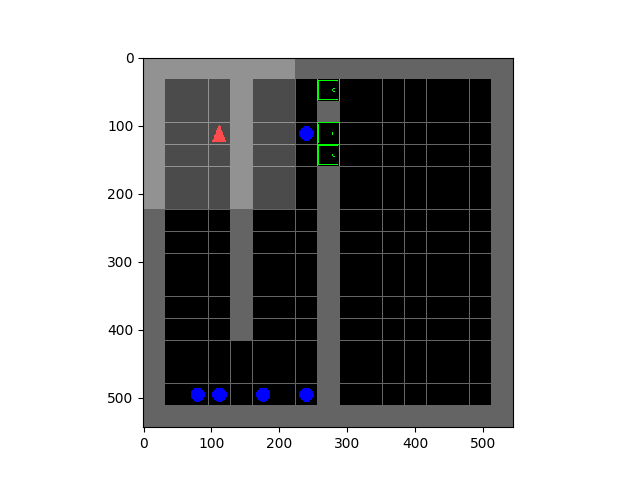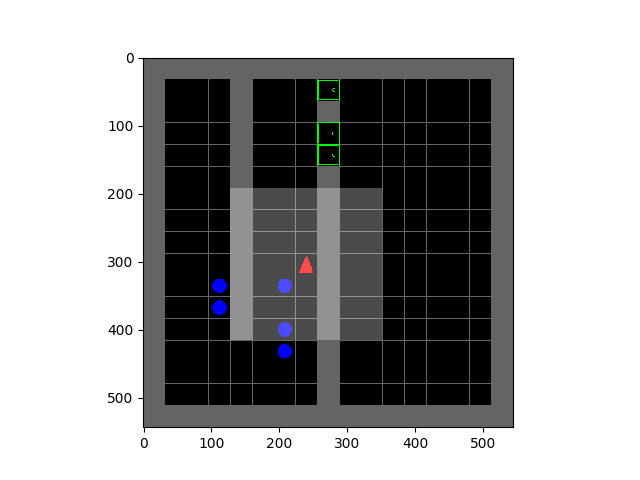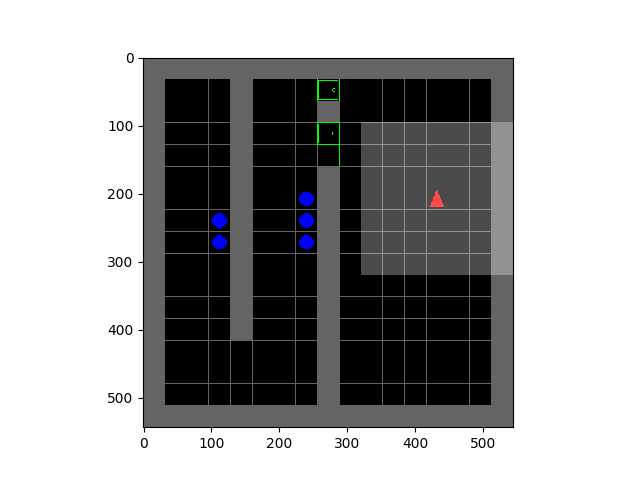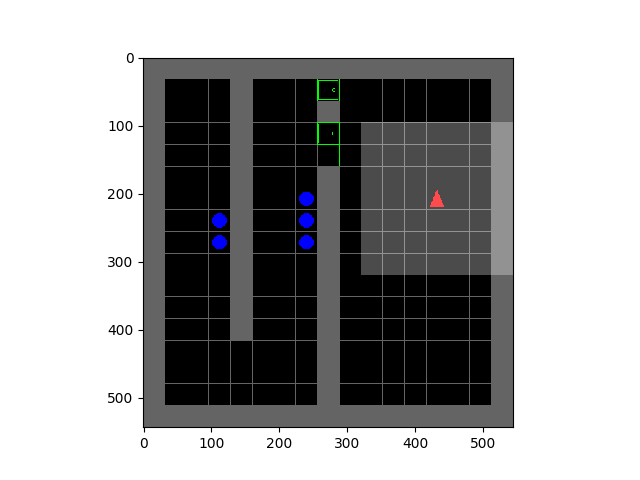 |
All living organisms carve out environmental niches within which they can maintain relative predictability amidst the ever-increasing entropy around them [schneider1994, friston2009]. Humans, for example, go to great lengths to shield themselves from surprise --- we band together in millions to build cities with homes, supplying water, food, gas, and electricity to control the deterioration of our bodies and living spaces amidst heat and cold, wind and storm. The need to discover and maintain such surprise-free equilibria has driven great resourcefulness and skill in organisms across very diverse natural habitats. Motivated by this, we ask: could the motive of preserving order amidst chaos guide the automatic acquisition of useful behaviors in artificial agents?